





















こんばんわ、ばいおデス☆
アフィリエイト活動でWeb情報を収集する際に、商品の情報をまとめたいな〜って思うことがありますよね!(?)
今回はスクレイピングによって、Web情報をCSV(またはXLSX)形式で出力する方法をご紹介します♪
Google Chrome拡張機能:web-scraper
拡張機能のインストール
Google Chromeの拡張機能「web-scraper」は、使用方法が各所に紹介されています♪
慣れてしまえばとても使いやすいツールと思いましたので、お試しあれ☆

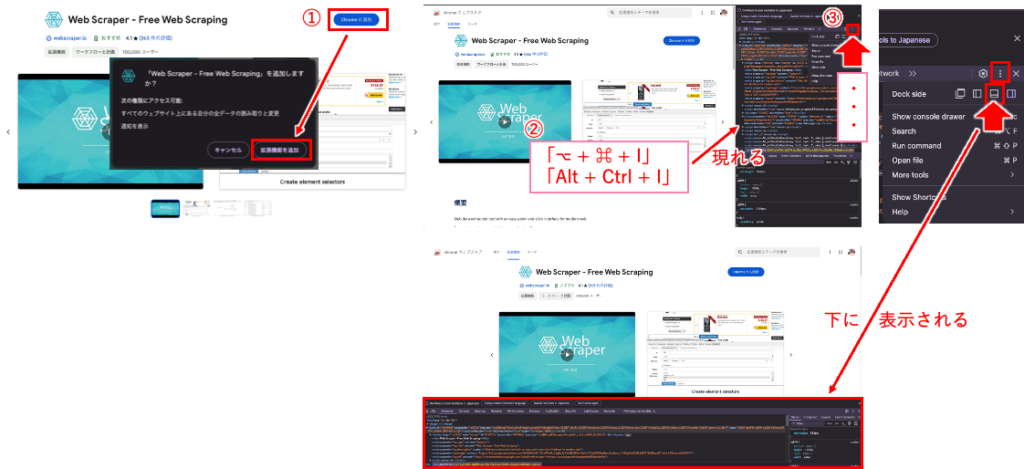
1)まず、上記サイトから拡張機能をインストールして有効化しておきます。
2)web-scraperをショートカット「⌥ + ⌘ + I(アイ)」で起動します。
※ Windowsの場合は「Alt + Ctrl + I」かも知れません!
3)縦の三点リーダ(・・・)を押すと設定が開くので、表示を下にします。
これで準備が整いましたので、スクレイピングしたいサイトにアクセスします。
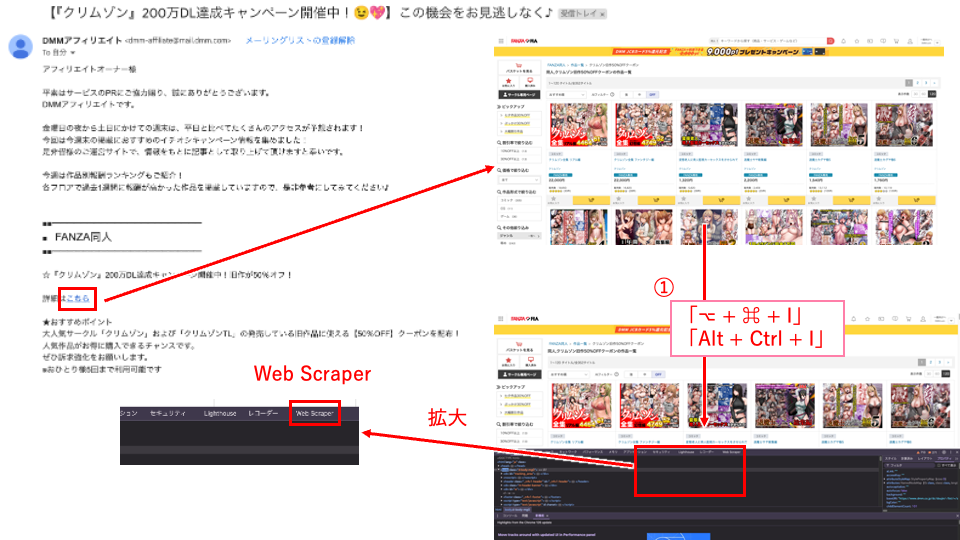
今回は、FANZAから案内の合ったサイトにしてみたいと思います。
スクレイピングの条件設定(sitemapの作成)
メールのリンクからサイトにアクセスし、「⌥ + ⌘ + I(アイ)」または「Alt + Ctrl + I」でWeb Scraperを表示させます。
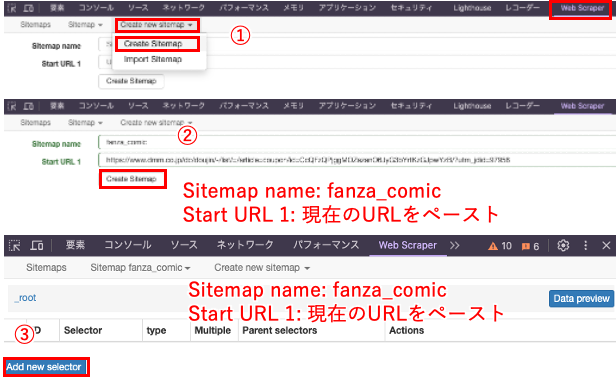
1)Web Scraper > Create new sitemap > Create Sitemapで新しく設定します。
2)Sitemap name: fanza_comic
Start URL 1: 現在のURLをペースト
Create Sitemap としました。
3)Add new selectorで情報を選択していきます。
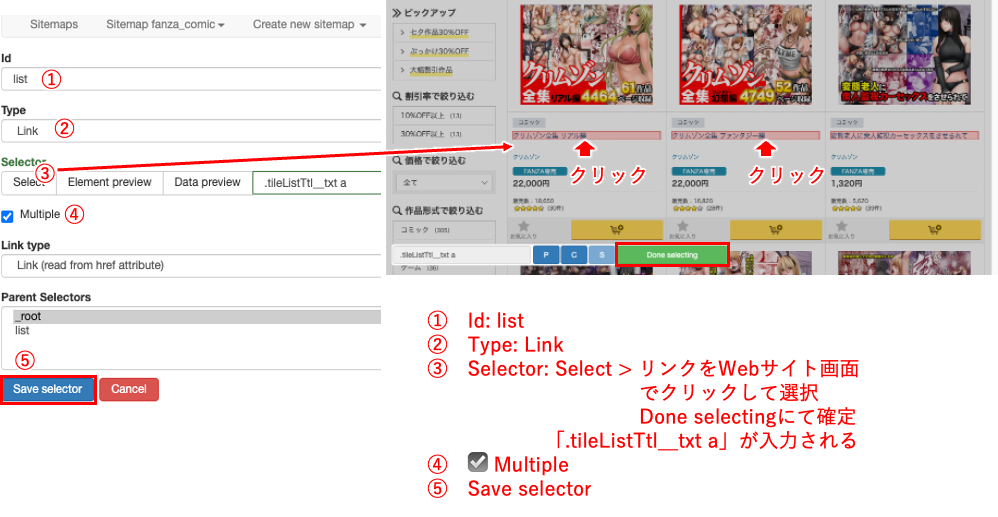
① Id: list
② Type: Link
③ Selector: Select > リンクをWebサイト画面
でクリックして選択
Done selectingにて確定
「.tileListTtl__txt a」が入力される
④ ☑ Multiple
⑤ Save selector
「Data preview」をクリックすると出力結果が表示されます♪
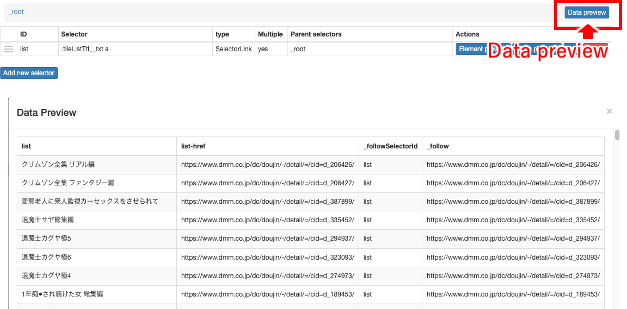
① listを押すとパスが「_root / list」となります。
② 上述と同様に、「Add new selector」で引き出す情報を選択します。
③ Webサイトの最初のコンテンツをクリックしておいて、詳細情報を表示させておきます。
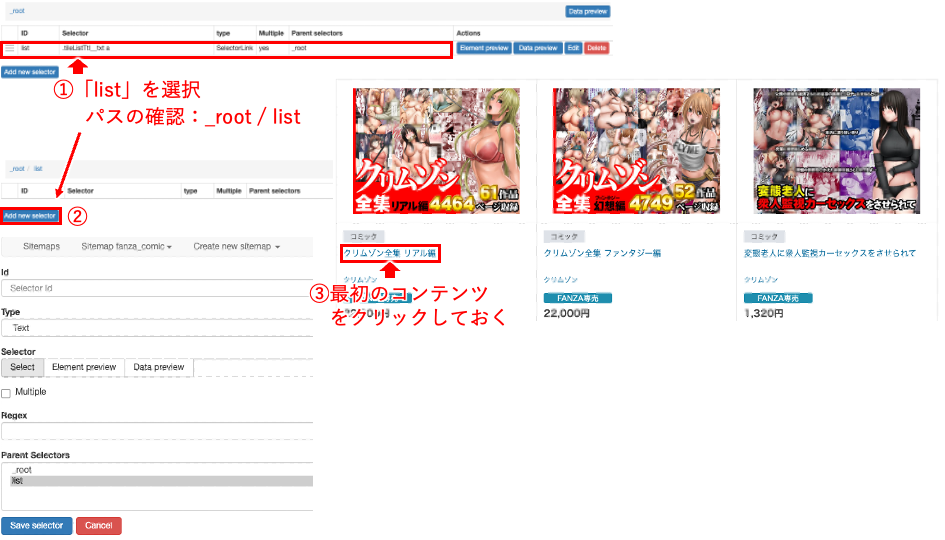
① Id: タイトル
② Type: Text
③ Selector: Select > タイトルをWebサイト画面
でクリックして選択
Done selectingにて確定
「h1」が入力される
④ □ Multiple
⑤ Save selector
⑥ Data preview で情報が取得できているかを確認します。
あとはこの繰り返して、サイトから欲しい情報を主に「Text」で抜き出してきます。
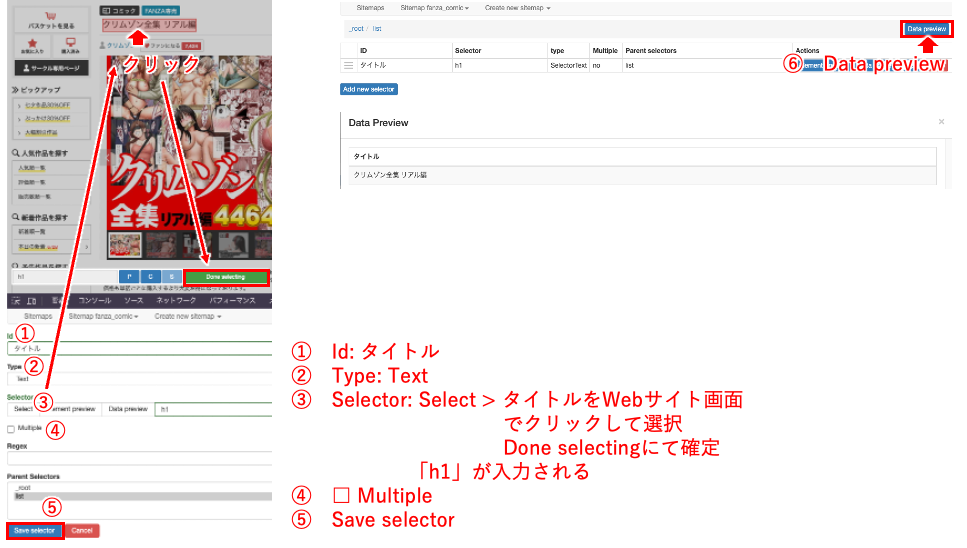
お好みの設定は完成しましたか??
ばいお は以下のようにしてみましたので参考になれば幸いです。
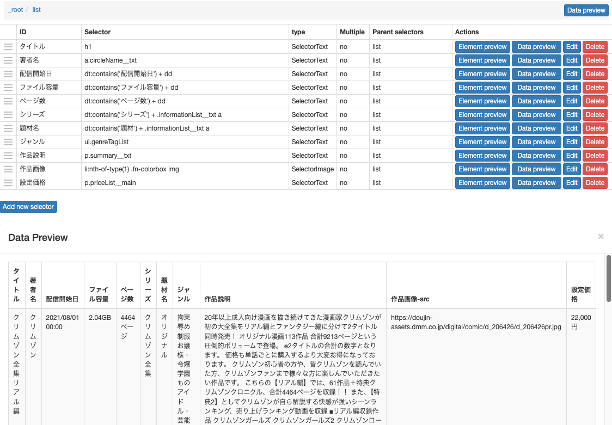
スクレイピング実行〜データのダウンロード
いよいよ実行していきます♪
準備として、スクレイピングの大元のサイト(root)にアクセスしておきます。
今回は 「同人,クリムゾン旧作50%OFFクーポンの作品一覧」 です。

実行前にデータプレビューを確認しておいて下さいね♪
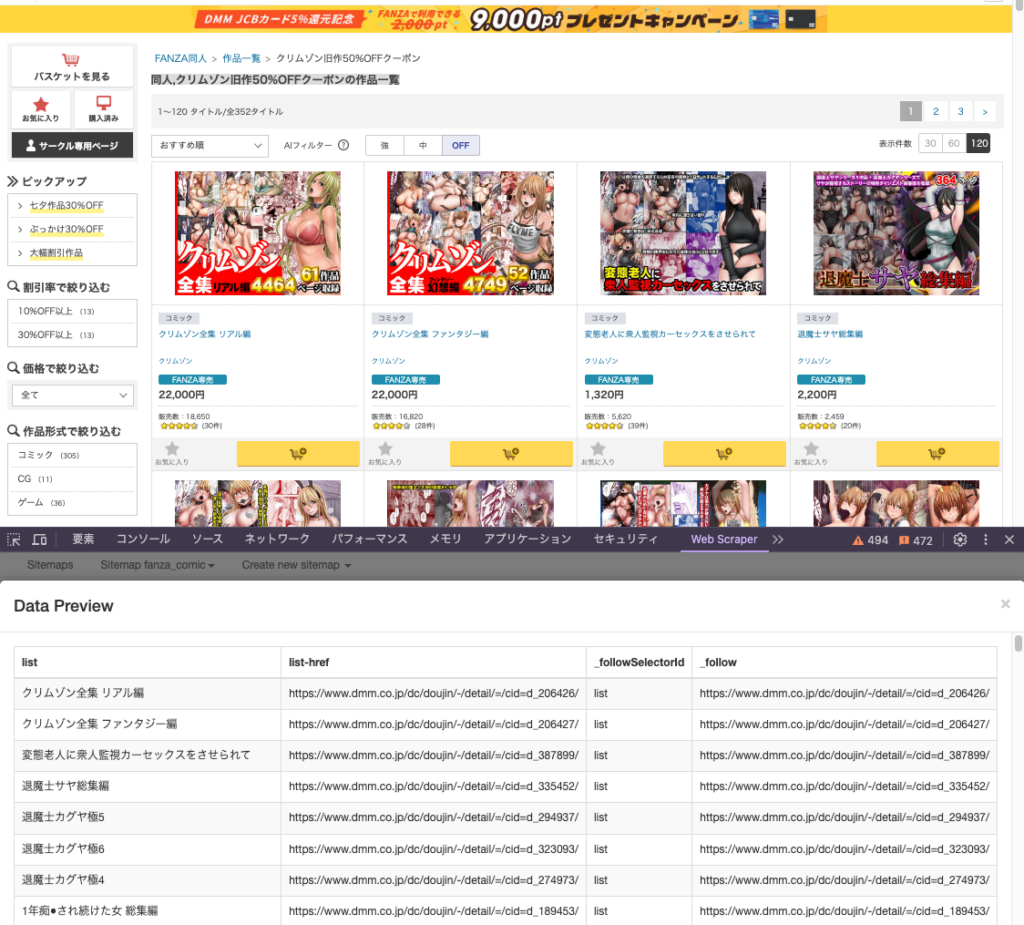
① Edit metadataで「root」となるStart URL 1を指定できますので確認しておくとよいですよ♪
② Scrape > Start scrapingで実行されます。
※ おおよそ15〜20分かかるようですので、気長に待ちましょう☆
③ Refresh Dataで結果を確認できます。
④ Export dataで「.XLSX」形式や「.CSV」形式のデータがダウンロードできます。
開くと情報が一覧となって表示されますよ♪
スクレイピング条件(Sitemap)の出力
今回のスクレイピング条件(Sitemap)を出力して、新たに入力して利用することができます☆
少しだけ条件を変更したいときには、一から作成しなくて済むのでオススメですよ。
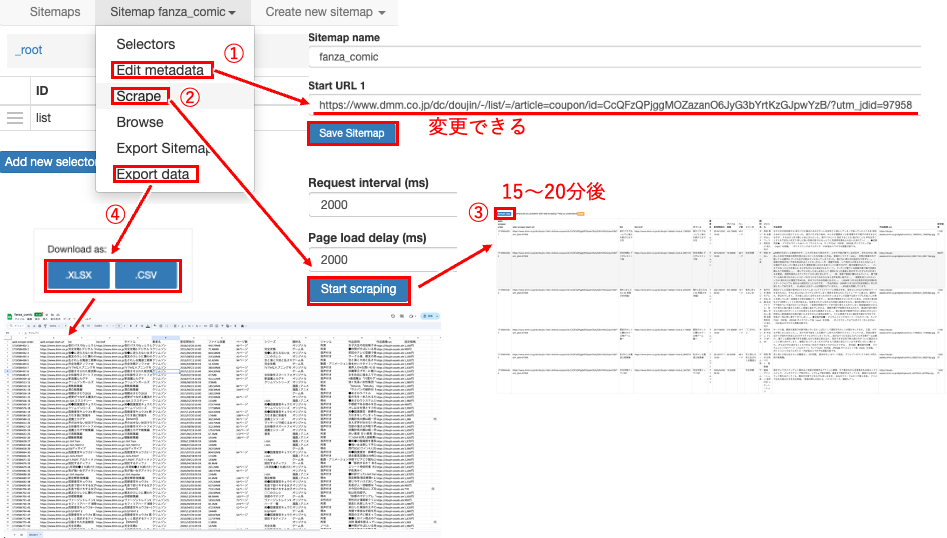
① Sitemap fanza_comicのメニューを開きます。
② Export Sitemapを選択すると、条件がテキストデータで確認できます。
コピーしておきましょう♪
{"_id":"fanza_comic","startUrl":["https://www.dmm.co.jp/dc/doujin/-/list/=/article=coupon/id=CcQFzQPjggMOZazanO6JyG3bYrtKzGJpwYzB/?utm_jdid=97958"],"selectors":[{"id":"list","linkType":"linkFromHref","multiple":true,"parentSelectors":["_root"],"selector":".tileListTtl__txt a","type":"SelectorLink"},{"id":"タイトル","multiple":false,"parentSelectors":["list"],"regex":"","selector":"h1","type":"SelectorText"},{"id":"著者名","multiple":false,"parentSelectors":["list"],"regex":"","selector":"a.circleName__txt","type":"SelectorText"},{"id":"配信開始日","multiple":false,"parentSelectors":["list"],"regex":"","selector":"dt:contains('配信開始日') + dd","type":"SelectorText"},{"id":"ファイル容量","multiple":false,"parentSelectors":["list"],"regex":"","selector":"dt:contains('ファイル容量') + dd","type":"SelectorText"},{"id":"ページ数","multiple":false,"parentSelectors":["list"],"regex":"","selector":"dt:contains('ページ数') + dd","type":"SelectorText"},{"id":"シリーズ","multiple":false,"parentSelectors":["list"],"regex":"","selector":"dt:contains('シリーズ') + .informationList__txt a","type":"SelectorText"},{"id":"題材名","multiple":false,"parentSelectors":["list"],"regex":"","selector":"dt:contains('題材') + .informationList__txt a","type":"SelectorText"},{"id":"ジャンル","multiple":false,"parentSelectors":["list"],"regex":"","selector":"ul.genreTagList","type":"SelectorText"},{"id":"作品説明","multiple":false,"parentSelectors":["list"],"regex":"","selector":"p.summary__txt","type":"SelectorText"},{"id":"作品画像","multiple":false,"parentSelectors":["list"],"selector":"li:nth-of-type(1) .fn-colorbox img","type":"SelectorImage"},{"id":"設定価格","multiple":false,"parentSelectors":["list"],"regex":"","selector":"p.priceList__main","type":"SelectorText"}]}
上記のなかで、startUrlを設定する部分があります。
このURLを変更することで、同様のスクレイピングができることになります。
「”startUrl”:[“https://www.dmm.co.jp/dc/doujin/-/list/=/article=coupon/id=CcQFzQPjggMOZazanO6JyG3bYrtKzGJpwYzB/?utm_jdid=97958“]」
まずは、上記をコピーしてインポートしてみます。
① Create new sitemapを押します。
② Import Sitemapを選択します。
③ 先程のExport Sitemapの情報をコピーペーストします。
すると、「Sitemap with this id already exists」というエラーが表示されます。
”_id”:”fanza_comic“の部分を編集して、異なる名称にする必要があります。
ついでにstartUrlも変更しておいても良いと思いますよ♪
④ ”_id”:”fanza_comic_rank”,
”startUrl”:[“https://www.dmm.co.jp/dc/doujin/-/list/=/limit=120/media=comic/section=mens/sort=sales/”]にして「Import Sitemap」を押します。
⑤ 「fanza_comic_rank」というSitemapが設定できました♪
まとめ
いかがでしたか?
この記事では、Google Chromeの拡張機能「Web Scraper」を用いて、サイトから商品の情報を簡単に取り出して収集・整理できる方法を紹介しました。
保存した情報の使い道はたくさんあると思います。
ブログ記事のネタとして、コピーペーストしても良いと思いますし、もう少し整理してまとめサイトにしても良いかも知れませんね♪
スクレイピングした情報を、WordPressの「投稿」に活用する方法を紹介したいと考えています☆
投稿後、しばらくは公開する予定ですので気になる方はチェックしてみて下さい♪
いつか、ダレかのナニかのためになれば幸いです♡
素材
Canva:アイキャッチ


コメント